
The addition of CI pipelines to Argonaut has been one of the major feature releases for us in the past year. We recently released a v2 that supports sequential and parallel deployments across environments. The pipeline-based workflow will also be a crucial part of deploying apps using Argonaut for the foreseeable future, and this technical blog delves into the implementation details of the feature. We look at everything from the objectives we set out with, the design constraints we had to work around, and the various tools used in the front end and back end. Lastly, we discuss future enhancements to further simplify and optimize the pipeline creation process.
Why pipelines?
Pipelines as a concept have long been used in computing to represent sequence of processes where output of one process automatically gets fed into input of other ones. This translates very well to how we as developers like to ship our products. First, we build our code where we have multiple build related checks running on it (e.g. linting, style guide checks etc.) and then we deploy it to our dev, QA, staging and prod environments based on various acceptance criteria that we have defined.

What tools are used?
Backend (Go)
Frontend (React, Typescript)
Implementation
We're excited to share the overall architecture, and some key insights into its implementation along with code snippets with you in the following sections.
Design Constraints
- The whole system should be event-driven.
- Users should be able to add and stitch various kinds of steps (build, deploy, scripts) in the pipeline. These steps will be referred to as pipeline jobs.
- Pipeline jobs should show actionable error logs if they fail to complete.
- Pipeline and pipeline jobs should maintain their present status and history.
- It should be possible to trigger jobs either automatically or manually.
- Job artifacts generated by the system should be compatible with broader standards, so dagger and k8s manifests should be used as the normalizing layer.
What is a pipeline and pipeline job for backend system?
A Pipeline is a Directed Acyclic Graph representation of various pipeline jobs. A job in a pipeline is a process that gets executed by our backend. This pipeline job process can be of various types e.g., build, deploy, script, etc.
A pipeline job can have multiple inputs, which it can use during its execution and outputs (also known as artifacts), which can be used by other pipeline jobs.
1type Pipeline struct { 2 Id string `json:"id"` 3 CreatedAt time.Time `json:"created_at"` 4 UpdatedAt time.Time `json:"updated_at"` 5 Name string `json:"name"` 6 OrganizationId string `json:"organization_id"` 7 TriggerMode PipelineTriggerMode `json:"trigger_mode" validate:"required" enums:"auto,manual"` 8 TriggerType PipelineTriggerType `json:"trigger_type" validate:"required" enums:"code_push"` 9 TriggerTypeId string `json:"trigger_type_id"` 10 TriggerRules TriggerRules `json:"trigger_rules"` 11 InputFields PipelineInputFields `json:"input_fields"` 12 PipelineGroupId string `json:"pipeline_group_id"` 13} 14 15type PipelineJob struct { 16 Id string `json:"id"` 17 CreatedAt time.Time `json:"created_at"` 18 UpdatedAt time.Time `json:"updated_at"` 19 PipelineId string `json:"pipeline_id"` 20 Name string `json:"name"` 21 Kind PipelineJobKind `json:"kind" validate:"required" enums:"git_docker_build,git_kube_deployment,custom"` 22 KindId string `json:"kind_id"` 23 DependsOn DependsOn `json:"depends_on"` 24 InputFields JobInputFields `json:"input_fields"` 25 Meta PipelineJobMeta `json:"meta"` 26} 27
A pipeline is executed after it gets triggered. There can be various types of triggers associated with a pipeline. One of the most common ones is code push to a remote repository hosted on a platform like GitHub or Gitlab.
Let’s understand this with an example. Assume that a user wants to trigger their pipeline when they push changes to their main branch on their GitHub Repository. Following is how we would associate their Github Repo information with a pipeline.
1{
2 "code_push_trigger": {
3 "branch": "main",
4 "context_paths": [
5 "."
6 ]
7 }
8}
9
Inside the pipeline, trigger_type would be code_push, trigger_type_id will store the Github repo’s id, and trigger_rules will store the information about the associated branch and other info like on what paths to trigger, etc.
Pipeline’s triggers are extensible. We can easily switch the method of triggering a pipeline by changing the trigger_type field e.g., Web-hooks etc.
Pipelines can either be triggered automatically, like in the GitHub push case above, or manually by the users. This information is stored in the trigger_mode field.
We can feed inputs to pipelines through the input_fields field. To understand it, we can look at the case of Auto Trigger Types. Here we defined the input_fields to have branch and commit_sha, which is then required by the pipeline before triggering it.
How are pipeline jobs mapped and stored?
A Pipeline job can be easily understood by relating it to concepts that we all know and use in our day-to-day work. The build is a kind of pipeline job. Similarly, deploy is a kind of pipeline job. A user can add a custom bash script to run in between, which is also a pipeline job.
All kinds of pipeline jobs that we support are defined by the PipelineJobKind enum.
1type PipelineJob struct { 2 Id string `json:"id"` 3 CreatedAt time.Time `json:"created_at"` 4 UpdatedAt time.Time `json:"updated_at"` 5 PipelineId string `json:"pipeline_id"` 6 Name string `json:"name"` 7 Kind PipelineJobKind `json:"kind" validate:"required" enums:"git_docker_build,git_kube_deployment,custom"` 8 KindId string `json:"kind_id"` 9 DependsOn DependsOn `json:"depends_on"` 10 InputFields JobInputFields `json:"input_fields"` 11 Meta PipelineJobMeta `json:"meta"` 12} 13
A field that requires our attention first is the kind_id. Every pipeline job has this field, and we should understand what this field is and how it is different from a job’s id.
As we know that a pipeline job can be of various kinds, e.g., build, deployment, custom_script, etc. In our system, all these kinds are actual entities whose information is stored in their respective database table. To link a job with that information, we use kind_id.
So, if a pipeline_job is of a kind build, then kind_id will point to the id of that build in builds table. If that went over your head (trust me, it goes over the heads of everyone who hears it for the first time), here is a pictorial representation of what I am talking about.

We use Meta fields in our tables to store any information that is not suited to have its own column in the DB.
How do we stitch multiple jobs together?
As we know that a pipeline is a Directed Acyclic Graph of jobs. All incoming edges to a job are stored in the depends_on field which stores an array of reference of other jobs.
Similarly to pipelines, every job has a field called input_fields. This field stores mapping from outputs of other pipeline jobs to inputs of the current job. Let’s go over a sample value of input_fields of a deploy job.
1[ 2 { 3 "value": null, 4 "property": "image_tag", 5 "value_ref": "job.build.outputs.image_tag" 6 }, 7 { 8 "value": null, 9 "property": "image", 10 "value_ref": "job.build.outputs.image" 11 }, 12 { 13 "value": null, 14 "property": "registry_id", 15 "value_ref": "job.build.outputs.registry_id" 16 } 17] 18
A deploy job in our system that is connected with a single build job has the above value stored in its input_fields. The property field defines the name of inputs in the current deploy job, whereas the value_ref field tells the system from where to fetch the value. value_ref has the convention job.<name>.outputs.<field_name> for jobs and pipeline.inputs.<field_name>
Keen-eyed readers would have noticed that a job can also take inputs from its overarching pipeline as well.
How are pipeline jobs queued and executed?
Whenever a pipeline is triggered, its jobs are queued in a queue. The queued jobs wait for their dependencies (from depends_on) to finish before getting processed by job processors. So, the init jobs (jobs that have no dependencies) are picked up first by our job processors.
Every kind of job has its own processor, which is responsible for executing it. Based on the kind of job, its execution environment is selected. For build jobs, CI tools are required, whereas for deploy jobs, CD tools are needed.
Therefore, we have built an abstraction layer over these CI and CD tools aptly named build and deploy, respectively.
Whenever a build job is triggered, we figure out the required CI (Github Actions in case of GitHub repos and Gitlab CI in case of Gitlab repos) and execute in that environment. We opted for using existing CI tools rather than reinventing our own as they already have wide toolings, and users might have their own workflows for builds.
A deploy job is executed through Argo CD. We won’t talk about details of how these build and deploy modules function as that would be out of scope for this post, but they are designed in a way that we can easily introduce other CI tools like Jenkins or other CD tools.
How are the results of job executions stored and displayed?
1type PipelineRun struct { 2 Id string `json:"id"` 3 CreatedAt time.Time `json:"created_at"` 4 UpdatedAt time.Time `json:"updated_at"` 5 PipelineId string `json:"pipeline_id"` 6 Input Inputs `json:"input"` 7 PipelineJobs []PipelineJob `json:"pipeline_jobs"` 8 Status PipelineStatus `json:"status" validate:"required" enums:"triggered,running,waiting,skipped,failed,cancelled,completed"` 9 State map[string]JobState `json:"state"` 10 OrganizationId string `json:"organization_id"` 11 TriggeredBy string `json:"triggered_by"` // User Info for manual trigger 12} 13
Every time a pipeline is triggered, its state and info are saved in pipeline_runs DB table. Here, we maintain the current state of all the jobs, status of the pipeline, the config of jobs at the time it was triggered (in pipeline_jobs), all inputs for the pipeline, and information about the user that triggered it (if triggered manually).
How do we maintain triggers across Github and Gitlab?
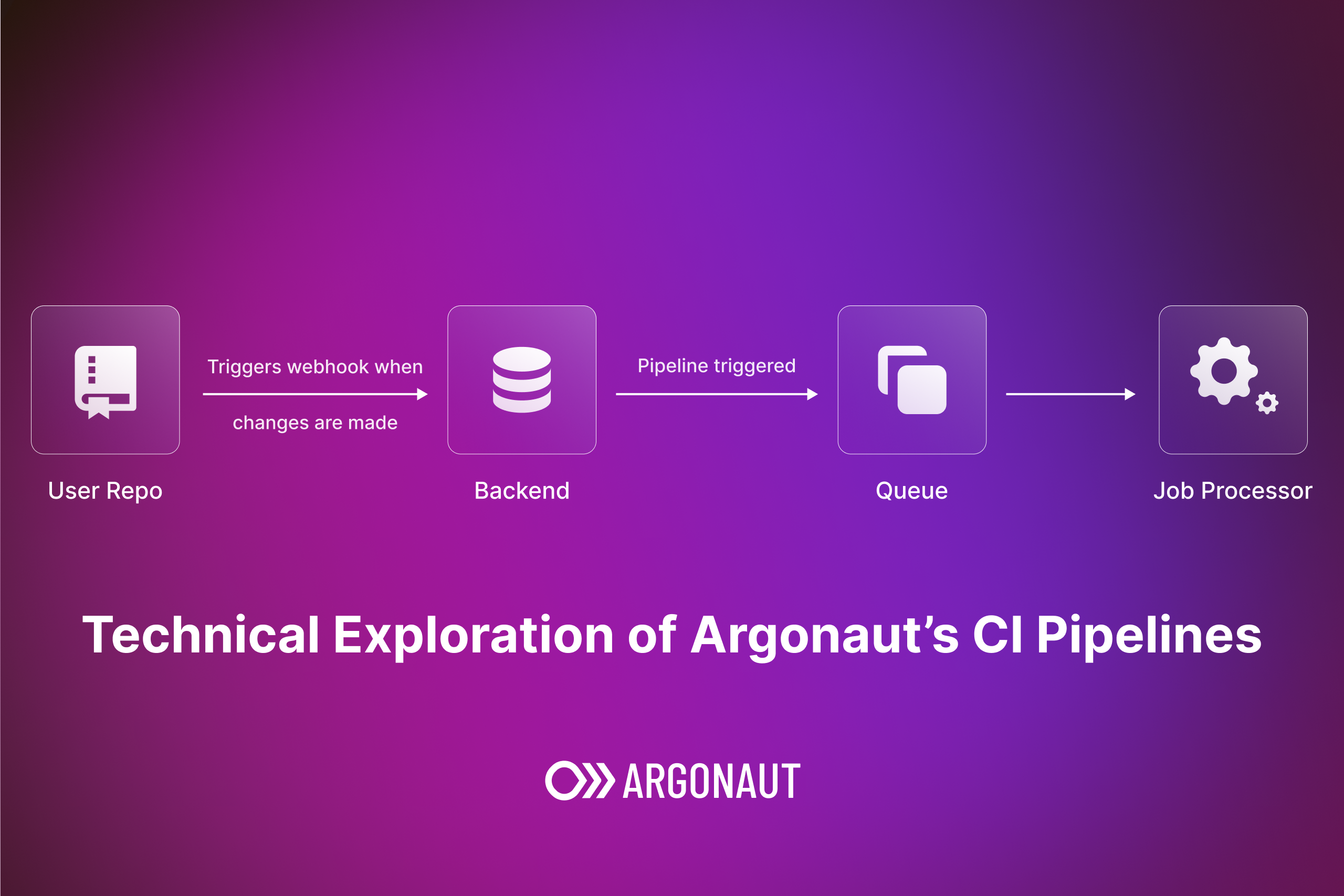
A pipeline can be configured to automatically trigger on code pushes to a repo. We currently support adding repos from Github and Gitlab. All of the VCS (Version Control Systems) logic is abstracted through a module called, you guessed it, VCS.
Whenever a user saves a pipeline, they associate a repository and a branch with it along with the trigger paths. Trigger paths are used to trigger the pipeline when updates happen in a specific location in the repo.
After a build is saved for the first time, we generate a GitHub Workflow / Gitlab CI file in the associated repo. This workflow uses our custom action, which is used to communicate with our backend.
Now when a code push happens, our VCS module gets notified by the VCS service through web-hooks. The web-hook carries information about the push i.e., branch, file, etc, which is matched with our saved configuration of pipeline triggers. If the match is successful, the pipeline is triggered.
How do we render nodes in the UI?
Let’s now shift our focus to how all this is shown to a user.
We use React Flow to render our pipelines on the UI. In React Flow, there are nodes and edges. A node requires a unique id and position, and an edge requires a source node and target node id.
After the API call for getting pipeline returns, we iterate over the list of pipeline_jobs field. Every job in the list is rendered as a node in the UI with its depends_on iterated over to create edges.
As our pipelines are directed acyclic graphs, we have to show directions on an edge. To do this, we use a feature in React Flow called Edge Markers.
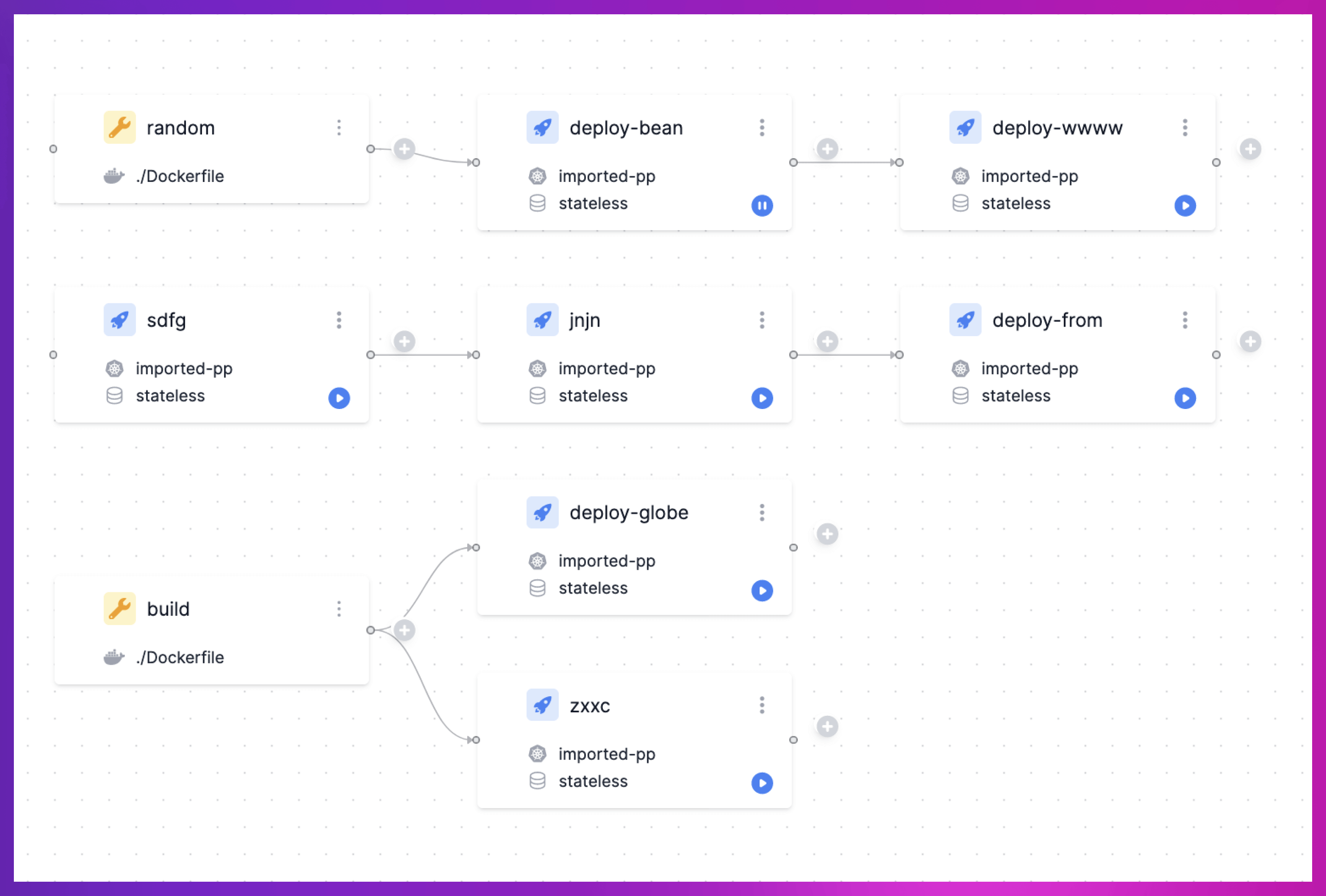
Placing new nodes and deleting nodes
Users can either add an init job node (which does not have a parent node) through a dedicated button or a child node by clicking on the Add button on a node.
Whenever a new node needs to be created, our algorithm first tries to place it on the same y coordinate as the parent node with an offset added for the x coordinate. However, before placing the node, we check for collisions with other nodes, in which case the Y coordinate is increased until there is no collision. Below is the algorithm that figures out the new position of a node.
1function findProperPos(node) {
2 // We don't have a node's width before adding it to the canvas so assuming a standard width here
3 const defaultNodeWidth = 260;
4 const defaultNodeHeight = 100;
5 const overlappingNode = allNodes.find(
6 (existingNode) =>
7 // Find if node intersects with existing node
8 existingNode.id !== node.id &&
9 existingNode.position.x < node.position.x + defaultNodeWidth &&
10 existingNode.position.x + existingNode.width > node.position.x &&
11 existingNode.position.y < node.position.y + defaultNodeHeight &&
12 existingNode.position.y + existingNode.height > node.position.y,
13 );
14 if (overlappingNode) {
15 node.position.y =
16 overlappingNode.position.y +
17 overlappingNode.height +
18 defaultInterNodeDistance.y;
19 return findProperPos(node);
20 }
21 return node.position;
22 }
23
Placing new nodes in action:
Whenever a node is deleted, all its outgoing edges are merged with its incoming edges. So, the parents of the node get connected with their children. This way, there are no orphan nodes in the pipeline.
1const deleteNode = async (nodeId: string) => {
2 const nodeToBeDeleted = reactFlowInstance.getNode(nodeId) as INode;
3
4 const childNodes = getOutgoers(
5 nodeToBeDeleted,
6 reactFlowInstance.getNodes(),
7 reactFlowInstance.getEdges(),
8 );
9
10 ...
11 ...Code related to processing deletion of various types of node
12 ...
13
14 reactFlowInstance.deleteElements({ nodes: [nodeToBeDeleted] });
15
16 for (const childNode of childNodes) {
17 // Remove the node to be deleted from the depends_on property of the child nodes
18 const childNodeDependsOn = childNode.data.pipelineJobMeta.depends_on;
19 if (childNodeDependsOn) {
20 childNode.data.pipelineJobMeta.depends_on = childNodeDependsOn.filter(
21 (jobName) => jobName !== nodeToBeDeleted.data.pipelineJobMeta.name,
22 );
23 }
24 }
25
26 };
27
Deleting a stage in action:
Handling Unsaved Changes
One of the things that we wanted to take care of in our design was handling unsaved changes in the pipeline screen. As a user has to input various fields and stitch various jobs together, it can be quite frustrating if they accidentally navigate to a different page or press reload before saving their changes.
In our design, we added a pill to provide instant feedback about if a user needs to save changes done by them.

We also wanted to block any unneeded navigation from the page, which we did by implementing a global dirty state handling mechanism. We have a global IsUIDirty variable, which, if true, kicks the following mechanism into action.
- We use react-router for our in-app navigation, and to block that, we used the code below.
1useEffect(() => {
2 // Ref: https://github.com/remix-run/history/blob/main/docs/blocking-transitions.md
3 if (isUIDirty) {
4 history.block((prompt) => {
5 if (
6 ignoreNestedNavigation &&
7 !prompt.pathname.match(blockRegexPattern) &&
8 (prompt.pathname.includes(location.pathname) ||
9 location.pathname.includes(prompt.pathname))
10 ) {
11 // If the navigation is to a modal or child component which changes the route, we should not display the modal as the state changes will be preserved.
12 return;
13 }
14 if (
15 ignoreRegexPattern &&
16 prompt.pathname.match(ignoreRegexPattern) &&
17 !prompt.pathname.match(blockRegexPattern)
18 ) {
19 // Components can provide regex patterns to indicate which routes should be ignored for navigation blocking
20 return;
21 }
22 setNextLocation(prompt.pathname);
23 setShowModal(true);
24 return "true";
25 });
26 } else {
27 // Removes navigation block
28 history.block(() => {
29 return;
30 });
31 }
32
33 return () => {
34 history.block(() => {
35 return;
36 });
37 };
38 }, [history, isUIDirty]);
39
- To block browser-level navigation events like page reloads and tab closing, we use the
beforeunloadevent listener. Note that we are also appending * in our tab title to further indicate to users that there are unsaved changes in the UI.
1const handleBeforeUnload = useCallback((event) => {
2 event.preventDefault();
3 return (event.returnValue = "Are you sure you want to leave?");
4 }, []);
5
6 useEffect(() => {
7 /* Logic for browser level user interactions */
8 if (isUIDirty) {
9 window.addEventListener("beforeunload", handleBeforeUnload);
10 if (!document.title.endsWith("*")) {
11 document.title = `${document.title}*`;
12 }
13 } else {
14 window.removeEventListener("beforeunload", handleBeforeUnload);
15 if (document.title.endsWith("*")) {
16 document.title = document.title.slice(0, -1);
17 }
18 }
19 }, [isUIDirty]);
20

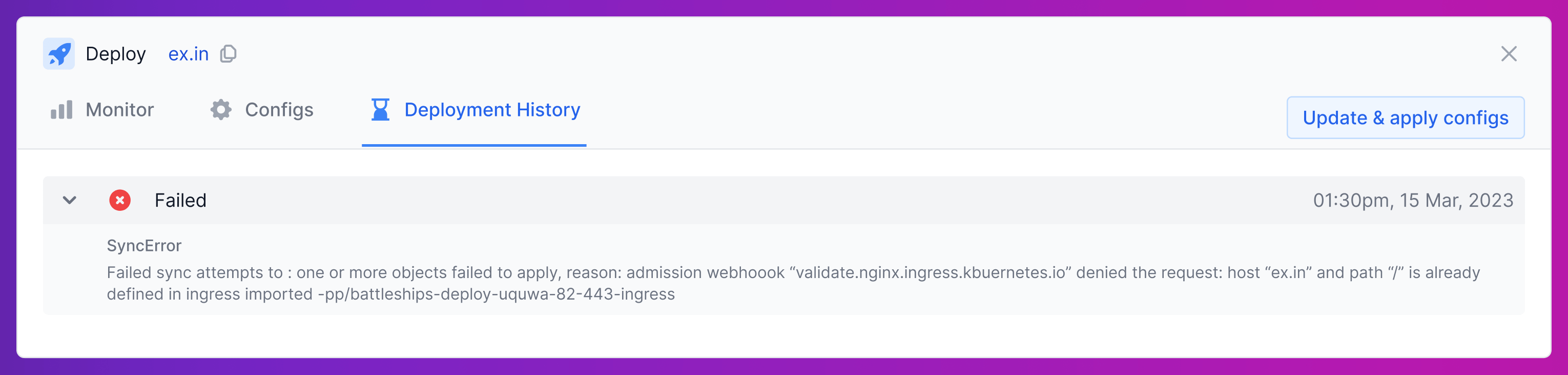
How are pipeline errors displayed?
State field in PipelineRun stores the latest state of all the jobs in the pipeline. If a job fails, the error message associated with it also gets saved in the field, which can then be easily displayed to the user in our UI.
Things to come in the future
In summary, we've taken you through the intricacies of our comprehensive pipelining system at Argonaut. We have covered how the system functions, the execution of pipeline jobs, and our approach to managing unsaved changes.
Looking ahead, we're steadily working on improving our system to better meet your needs. Here are some enhancements that are part of our roadmap:
Pipeline Templates: To simplify the creation of new pipelines.
Custom Scripts: This will allow for more flexibility by enabling you to run your own scripts in the pipeline jobs.
Delays in Job Execution: This will help in better management of workloads.
Web-hooks: We plan on expanding the triggering options for pipelines.
Infra Inclusion: To make our platform even more versatile.
Approval Flow and Jira/Linear Integration: This will enhance collaboration and project management within our pipelining system.
As a committed partner in your cloud journey, we're continuously elevating your Argonaut experience. We've optimized our pipeline feature and have big upcoming changes in infra management and cost visibility—making success inevitable for you. Gear up to make the most of these exciting innovations, as we can't wait to witness the incredible things you'll accomplish with Argonaut!